HTML to Markdown Scraping Workflow
Manual workflow that fetches HTML content from a URL and converts it into clean Markdown.
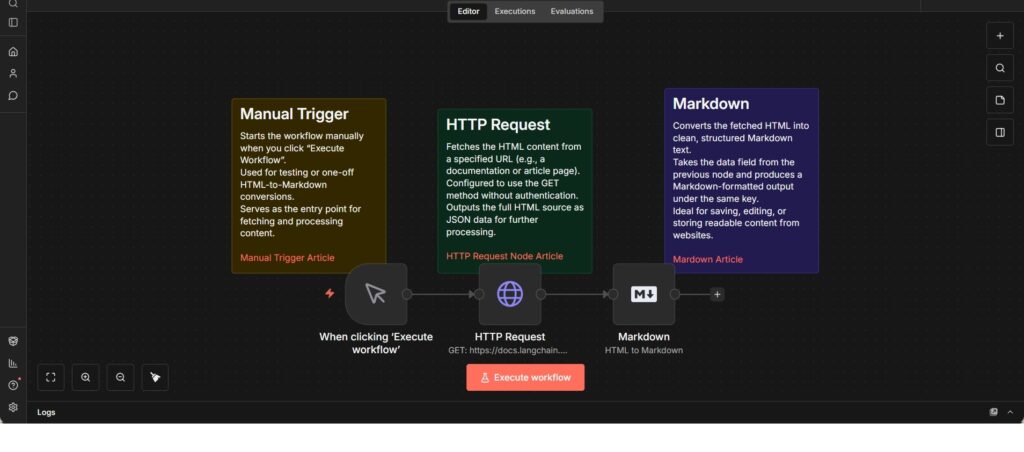
This workflow provides a simple utility pipeline for converting web-based HTML content into structured Markdown. It is triggered manually and is primarily used for testing, ad-hoc scraping, or one-off content transformations.
When executed, the workflow sends an HTTP GET request to a specified URL and retrieves the raw HTML content of the page. The response is passed directly to a Markdown conversion step, which transforms the HTML into a clean, readable Markdown format while preserving the document structure.
The resulting Markdown output can be used for documentation, note-taking, ingestion into knowledge bases, or further processing in downstream workflows such as RAG pipelines. The workflow is intentionally kept minimal, focusing only on content retrieval and format conversion without persistence or enrichment logic.
This setup is useful whenever readable text representations of web content are needed quickly and reproducibly.