Lokaler RAG-Chatbot für PDF-Dokumente mit Ollama und In-Memory-Vektorstore
Retrieval-Augmented-Generation-Workflow für konversationelle Fragenbeantwortung über PDF-Dokumente mit vollständig lokalem Ollama-Stack.
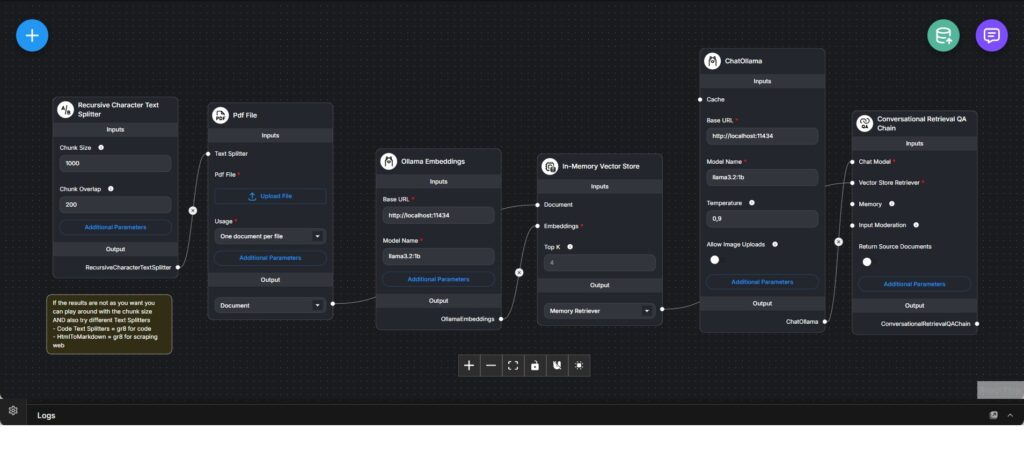
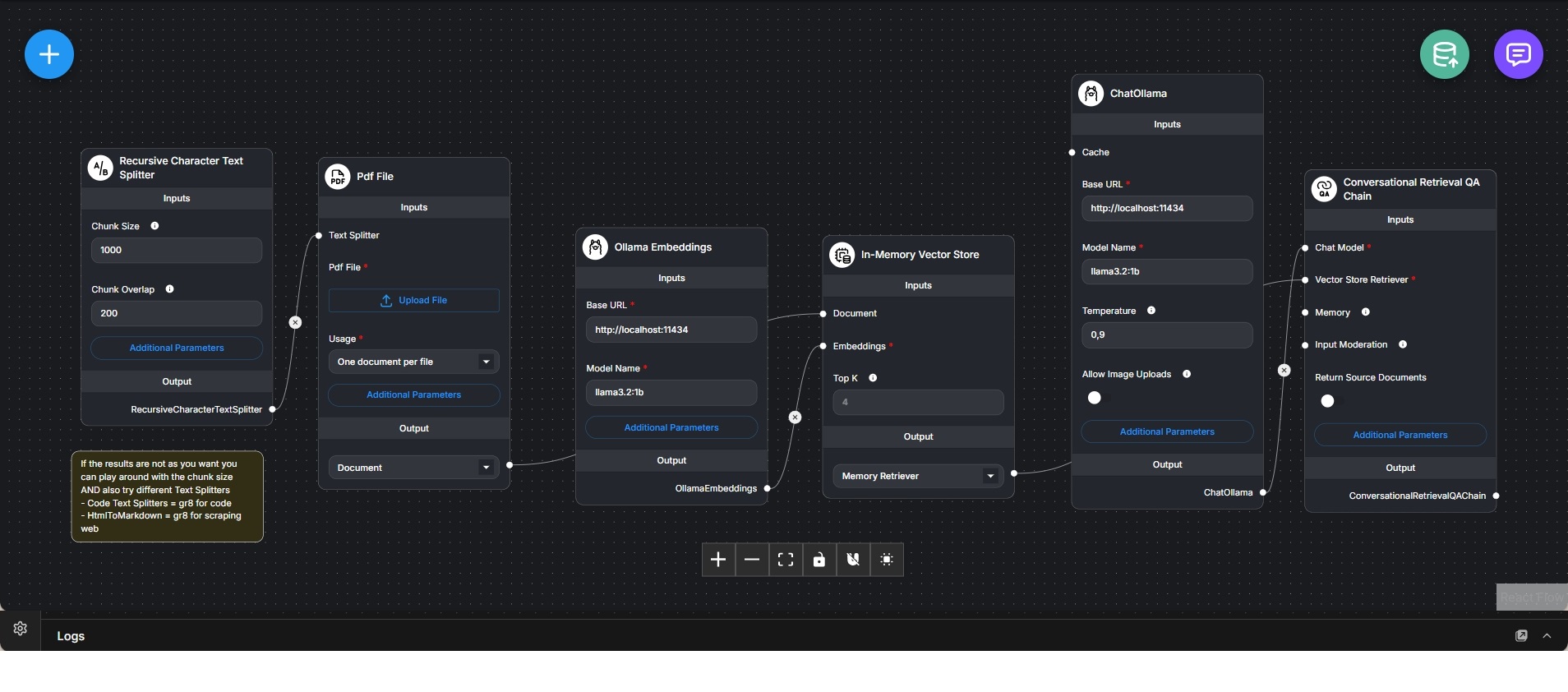
Dieser Workflow implementiert einen vollständigen lokalen Retrieval-Augmented-Generation-(RAG)-Chatbot, der Fragen auf Basis hochgeladener PDF-Dokumente beantwortet. Er zeigt den gesamten Prozess von der Dokumentenaufnahme über Embedding und Retrieval bis hin zur konversationellen Antwortgenerierung – ohne externe Cloud-Dienste.
Der Ablauf beginnt mit dem Upload einer PDF-Datei. Das Dokument wird mithilfe eines rekursiven Character-Text-Splitters in überlappende Textsegmente zerlegt. Chunk-Größe und Überlappung sind konfigurierbar und ermöglichen eine Feinabstimmung zwischen Kontexttreue und Retrieval-Genauigkeit.
Die einzelnen Textsegmente werden mit einem lokal betriebenen Ollama-Embedding-Modell in Vektoren umgewandelt. Diese Embeddings werden in einem In-Memory-Vektorstore gespeichert, der schnelle Ähnlichkeitssuchen während der Anfrageverarbeitung erlaubt. Der In-Memory-Ansatz eignet sich besonders für Prototyping und lokale Tests.
Eine Conversational-Retrieval-QA-Chain verbindet den Vektor-Retriever mit einem lokalen Ollama-Chatmodell. Bei einer Nutzerfrage werden die semantisch relevantesten Textsegmente aus dem Vektorstore abgerufen und dem Sprachmodell als Kontext zur Verfügung gestellt.
Das Sprachmodell erzeugt Antworten, die explizit auf den abgerufenen Dokumentinhalten basieren, anstatt ausschließlich auf vortrainiertem Wissen. Optional können die verwendeten Quelldokumente zurückgegeben werden, um Transparenz und Nachvollziehbarkeit zu erhöhen.
Der Workflow veranschaulicht ein zentrales RAG-Architekturmuster: die klare Trennung zwischen Dokumentverarbeitung (Embedding und Speicherung) und konversationellem Reasoning (Retrieval und Antwortgenerierung). Er eignet sich ideal für Dokumentanalyse, interne Wissensdatenbanken, technische Dokumentationen und datenschutzkritische Anwendungsfälle mit lokaler Ausführung.