Local RAG Chatbot for PDF Documents with Ollama and In-Memory Vector Store
Retrieval-Augmented Generation workflow that enables conversational question answering over PDF documents using a fully local Ollama-based stack.
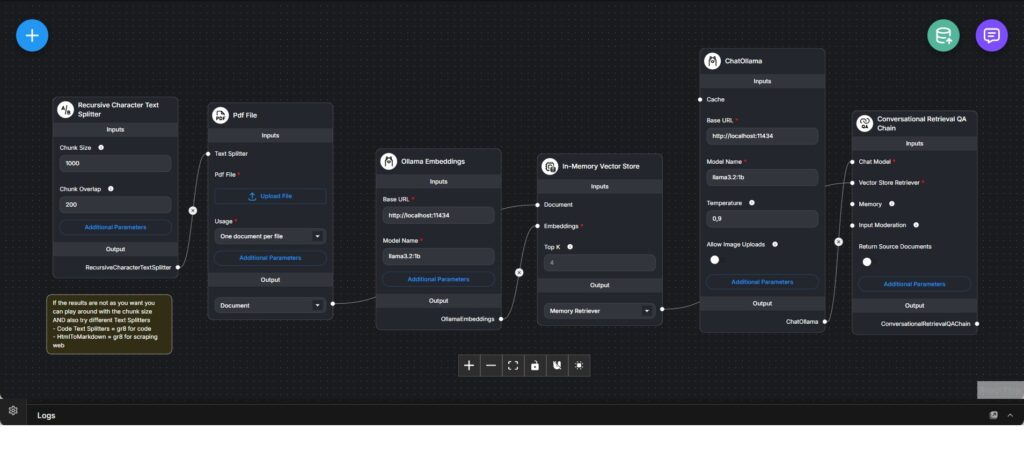
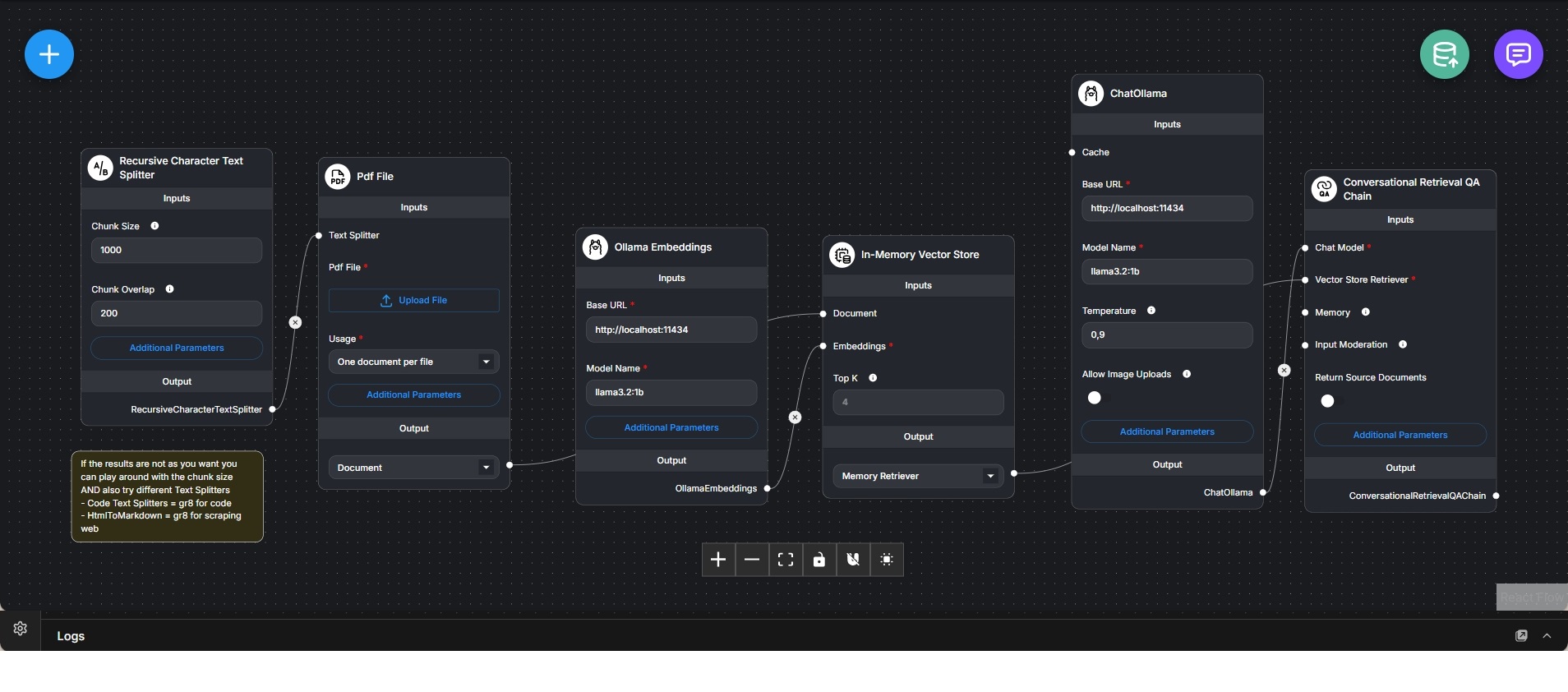
This workflow implements a complete local Retrieval-Augmented Generation (RAG) chatbot designed to answer questions based on the contents of uploaded PDF documents. It demonstrates the full lifecycle of document ingestion, embedding, retrieval, and conversational answering without relying on external cloud services.
The pipeline begins with a PDF file upload. The document is processed using a recursive character text splitter, which divides the text into overlapping chunks. Chunk size and overlap are configurable to balance semantic coherence with retrieval accuracy, allowing fine-tuning based on document structure and content density.
Each text chunk is converted into vector embeddings using a locally hosted Ollama embedding model. These embeddings are stored in an in-memory vector store, enabling fast similarity-based retrieval during query time. The in-memory approach emphasizes simplicity and speed for prototyping and local experimentation.
A conversational retrieval QA chain ties together the vector retriever and a local Ollama chat model. When a user asks a question, the system retrieves the most relevant document chunks based on semantic similarity and injects them into the prompt context used by the language model.
The chat model generates answers grounded in the retrieved document content rather than relying solely on pretrained knowledge. Optional source document return can be enabled to improve transparency and traceability of answers.
This workflow illustrates a core RAG architecture pattern: separating document understanding (embedding and storage) from conversational reasoning (retrieval and response generation). It is well suited for document exploration, internal knowledge bases, technical manuals, and private data scenarios where local execution and data privacy are essential.