Strukturierte Listengenerierung mit Ollama und Custom Output Parser
Lokaler Workflow zur Umwandlung einer freien Modellantwort in eine strukturierte Liste mithilfe eines benutzerdefinierten Output-Parsers.
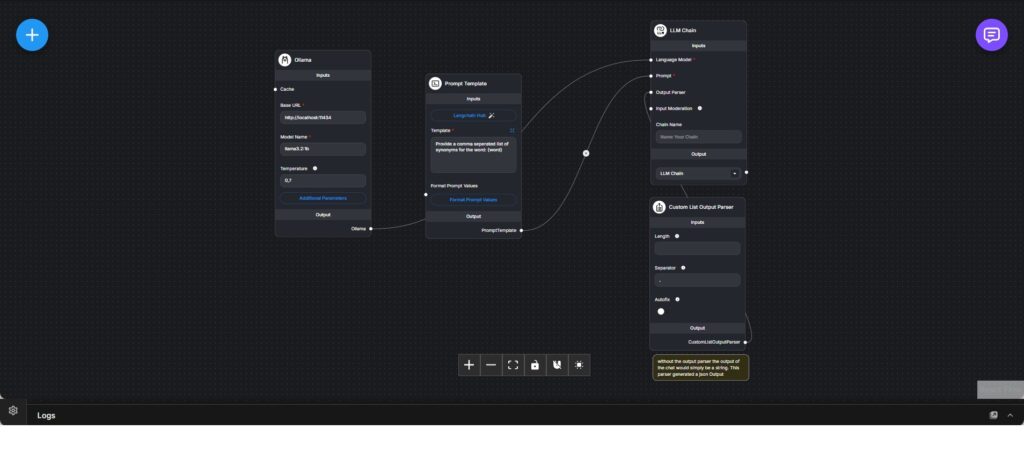
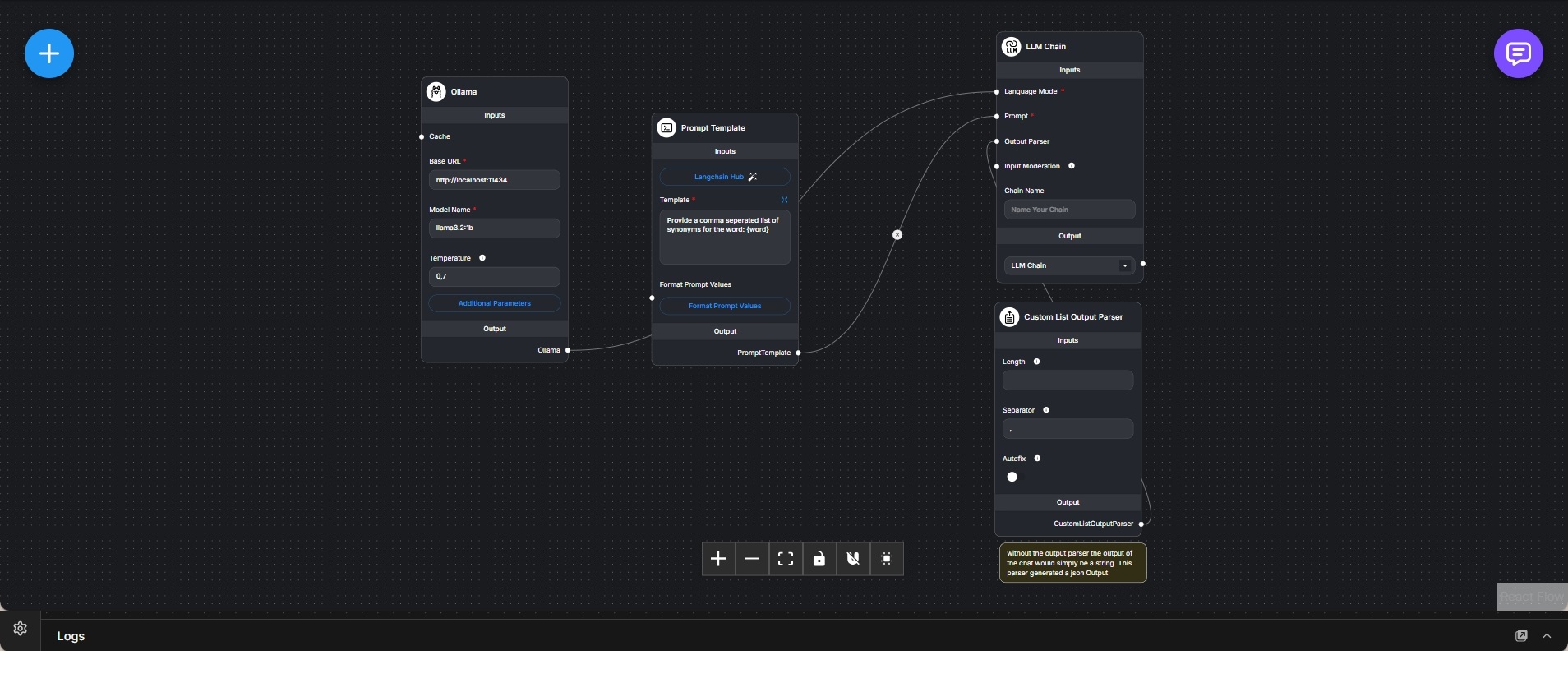
Dieser Workflow zeigt, wie eine unstrukturierte Antwort eines Sprachmodells in ein vorhersagbares, maschinenlesbares Format überführt werden kann. Der Fokus liegt bewusst auf Ausgabekontrolle und nicht auf Konversation, Gedächtnis oder Agentenlogik.
Ein lokal betriebenes Ollama-Sprachmodell fungiert als Backend. Über eine einfache Prompt-Vorlage wird das Modell angewiesen, eine durch Kommas getrennte Liste von Synonymen für ein gegebenes Wort zu erzeugen. Die Prompt-Struktur erlaubt natürliche Sprache, bleibt aber gut parsebar.
Der LLM-Chain-Knoten kombiniert Prompt-Vorlage und Sprachmodell zu einer Ausführungseinheit. Ohne Parser würde das Ergebnis lediglich als Textstring zurückgegeben.
Ein Custom-List-Output-Parser ist an die Chain angebunden, um die Ausgabe zu normalisieren. Der Parser trennt die Antwort anhand eines definierten Separators und kann optional eine feste Listenlänge erzwingen. Eine Autofix-Funktion erhöht die Robustheit bei kleineren Abweichungen im Modelloutput.
Das Endergebnis ist eine strukturierte Liste (JSON-Array) anstelle von freiem Text. Dadurch kann die Ausgabe direkt für Automatisierungen, Validierungen, UI-Darstellungen oder Systemintegrationen verwendet werden.
Der Workflow verdeutlicht ein zentrales Architekturprinzip: Sprachmodelle werden für die Generierung genutzt, während Struktur und Verlässlichkeit durch deterministische Parser sichergestellt werden. Ideal eignet sich dieser Ansatz für Keyword-Erweiterung, Taxonomie-Erstellung, Tag-Extraktion und kontrollierte Content-Pipelines.