Rechnungsanalyse-Workflow mit strukturierter Ausgabeverarbeitung
Dokumentenanalyse-Workflow zur Extraktion strukturierter Rechnungsdaten mithilfe eines Sprachmodells und eines schema-basierten Output-Parsers.
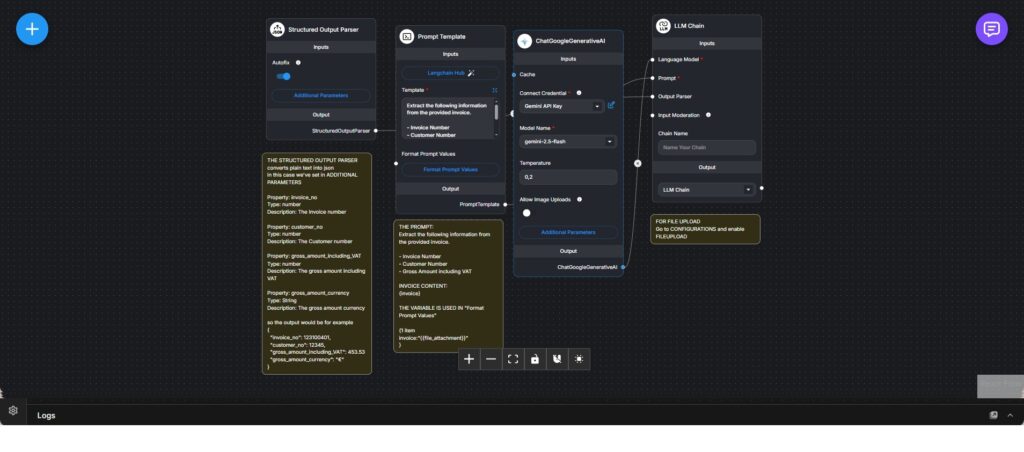
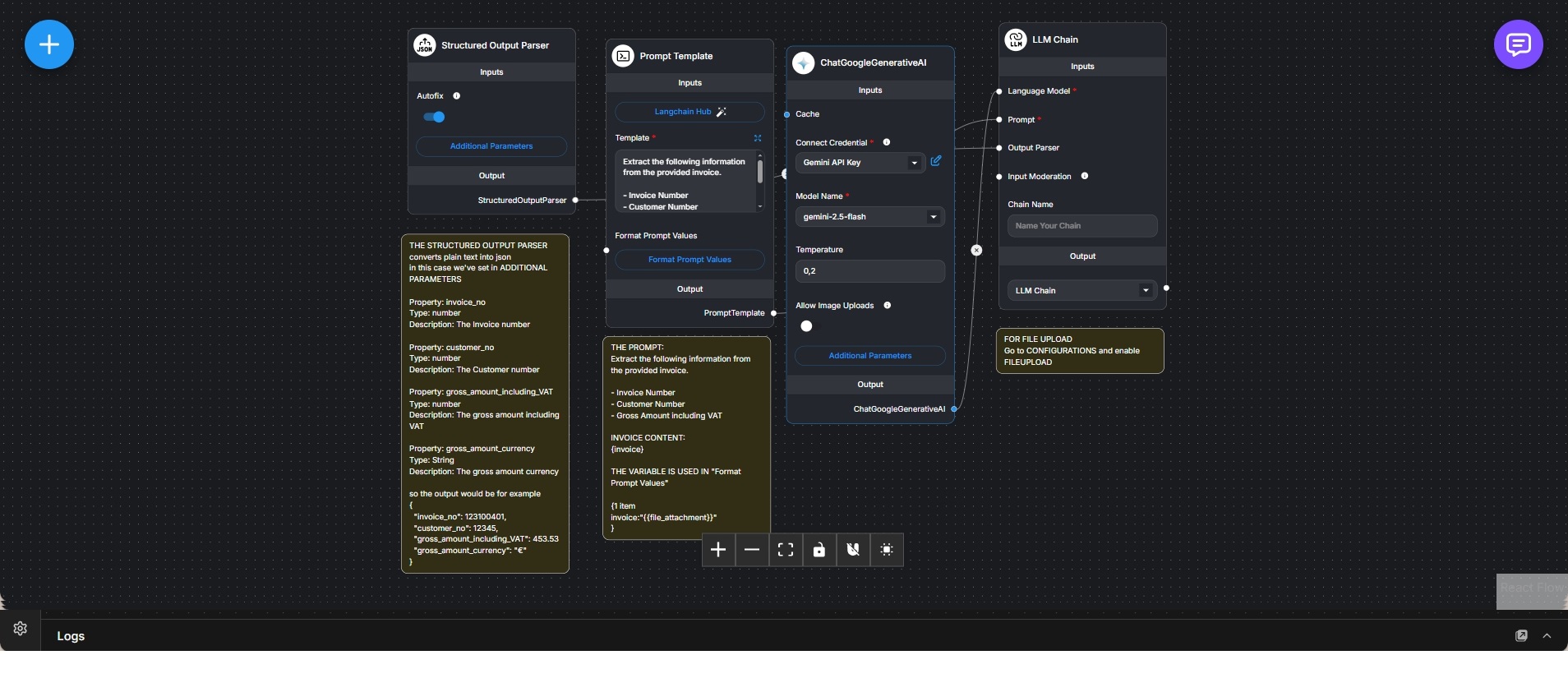
Dieser Workflow implementiert eine Dokumentenanalyse-Pipeline, die darauf ausgelegt ist, strukturierte Informationen aus Rechnungen zu extrahieren. Der Fokus liegt auf deterministischer Ausgabe statt auf Konversation, wodurch sich der Workflow besonders für nachgelagerte Automatisierung eignet.
Ein hochgeladenes Rechnungsdokument wird in eine Prompt-Vorlage eingebettet, die das Sprachmodell explizit anweist, vordefinierte Felder wie Rechnungsnummer, Kundennummer, Bruttobetrag inklusive Mehrwertsteuer und Währung zu extrahieren. Der Prompt ist bewusst eng gefasst, um nur die benötigten Informationen zu erzeugen.
Ein Structured-Output-Parser definiert ein festes Schema für das erwartete Ergebnis. Jedes Feld ist typisiert und beschrieben, sodass die Textausgabe des Modells in ein vorhersehbares JSON-Objekt überführt werden kann. Eine automatische Korrekturfunktion erhöht die Robustheit bei geringfügigen Abweichungen der Modellausgabe.
Das Sprachmodell wird über eine LLM-Chain ausgeführt, die Prompt-Vorlage, Modellkonfiguration und Output-Parser in einem Schritt kombiniert. Die Modellparameter sind auf geringe Kreativität ausgelegt, um Genauigkeit und Konsistenz zu priorisieren.
Das Ergebnis ist eine saubere, maschinenlesbare Datenstruktur, die direkt von Buchhaltungssystemen, Prüfmechanismen oder weiteren Automatisierungen genutzt werden kann. Der Workflow trennt Dokumenteneingang, Extraktionslogik, Modellausführung und Ausgabeverarbeitung klar voneinander.
Der Aufbau eignet sich besonders für Rechnungsverarbeitung, Dokumentendigitalisierung und Business-Workflows, bei denen strukturierte Daten aus unstrukturierten Dokumenten gewonnen werden müssen.