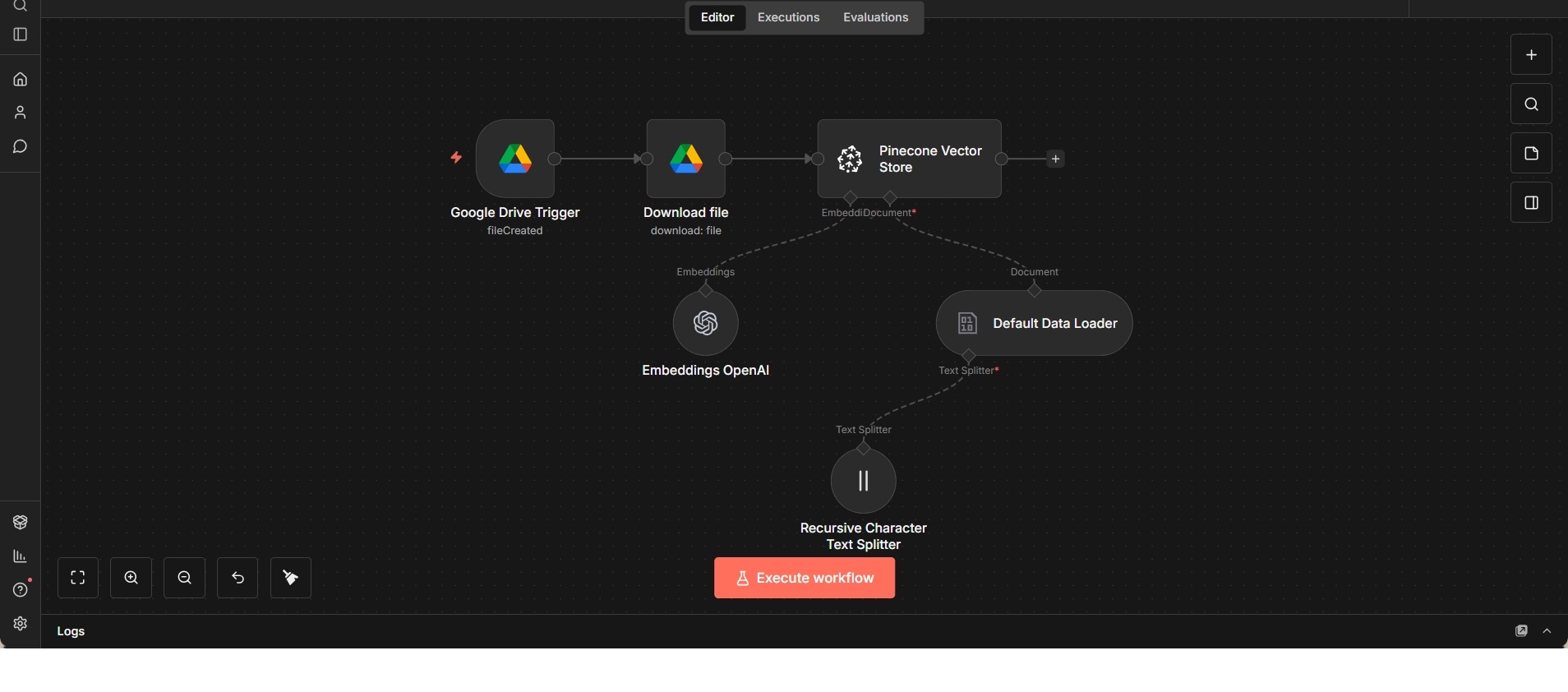
RAG-Ingestions-Workflow: Google Drive zu Pinecone
Automatisierter Ingestions-Workflow zur Indexierung neuer Google-Drive-Dateien in einer Pinecone-Vektordatenbank.
Dieser Workflow bildet eine klassische Ingestions-Pipeline für Retrieval-Augmented-Generation-(RAG)-Systeme. Er überwacht einen definierten Google-Drive-Ordner und reagiert automatisch, sobald neue Dateien hinzugefügt werden.
Nach der Erkennung wird die Datei heruntergeladen und durch einen strukturierten Ingestionsprozess geleitet. Der Inhalt wird in ein lesbares Format überführt und mithilfe eines rekursiven, zeichenbasierten Text-Splitters in sinnvolle Textabschnitte zerlegt. Dadurch bleiben semantische Zusammenhänge erhalten, während gleichzeitig konsistente Chunk-Größen sichergestellt werden.
Die erzeugten Textsegmente werden anschließend über ein Embedding-Modell in Vektorrepräsentationen umgewandelt und in einer Pinecone-Vektordatenbank gespeichert. Diese Struktur bildet die Grundlage für semantische Suche und spätere Abfragen durch RAG-Agenten oder andere KI-Systeme.
Der Workflow ist bewusst auf die reine Datenaufnahme beschränkt. Abfrage-Logik, Reasoning und Antwortgenerierung erfolgen in separaten Komponenten, was eine klare Trennung der Verantwortlichkeiten und eine einfache Wiederverwendung ermöglicht.
You must be logged in to post a comment.