RAG Ingestion Workflow: Google Drive to Pinecone
Automated ingestion pipeline that indexes newly uploaded Google Drive files into a Pinecone vector store.
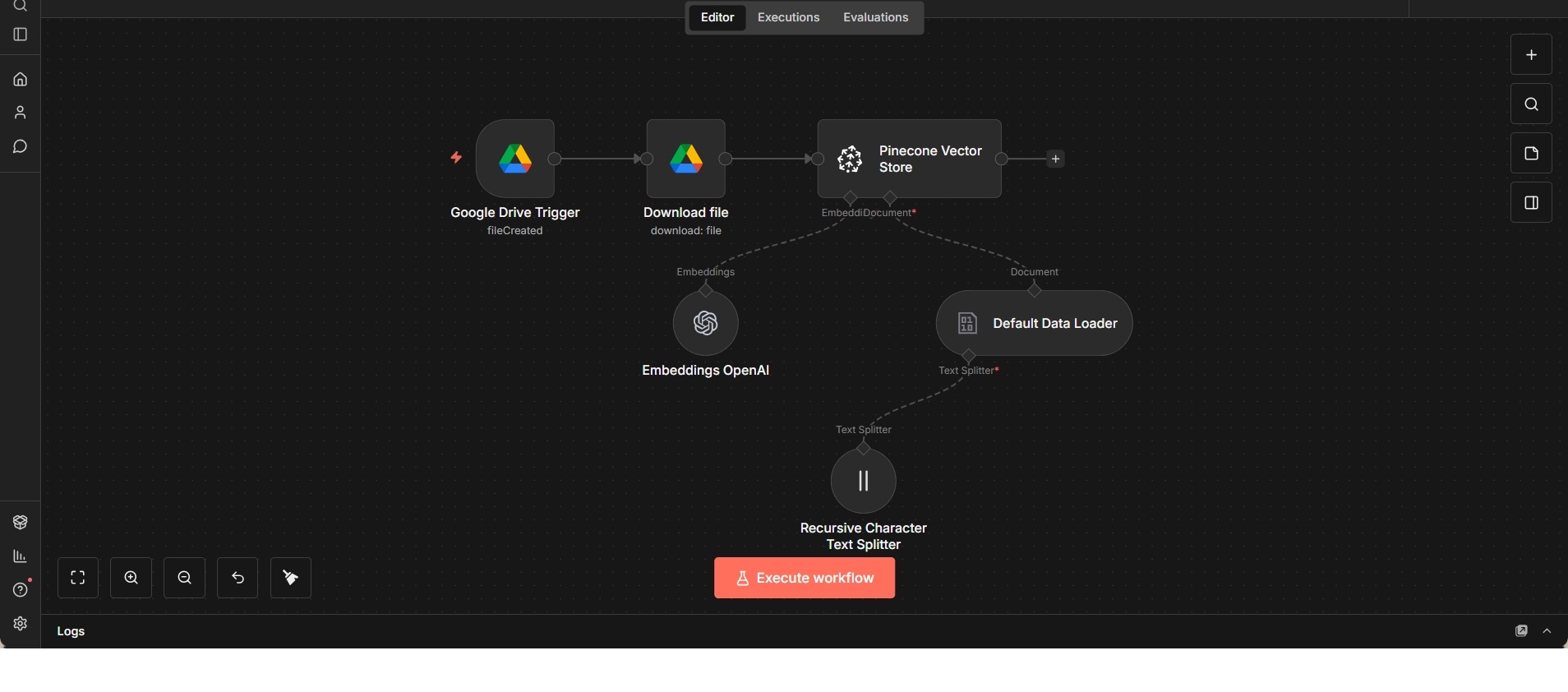
This workflow implements a document ingestion pipeline used for retrieval-augmented generation (RAG) setups. It continuously monitors a designated Google Drive location and reacts whenever a new file is created.
Once a file is detected, the workflow downloads the document and passes it through a structured ingestion process. The content is loaded into a readable format and split into manageable text chunks using a recursive character-based splitter. This ensures consistent chunk sizes while preserving semantic context across boundaries.
Each chunk is converted into vector embeddings using an embedding model and stored in a Pinecone vector database. The resulting index enables semantic search and downstream retrieval by RAG agents or other AI systems.
The workflow is intentionally focused on ingestion only. Querying, reasoning, and response generation are handled elsewhere, keeping responsibilities clearly separated and making the pipeline easy to reuse across different projects and agents.
You must be logged in to post a comment.