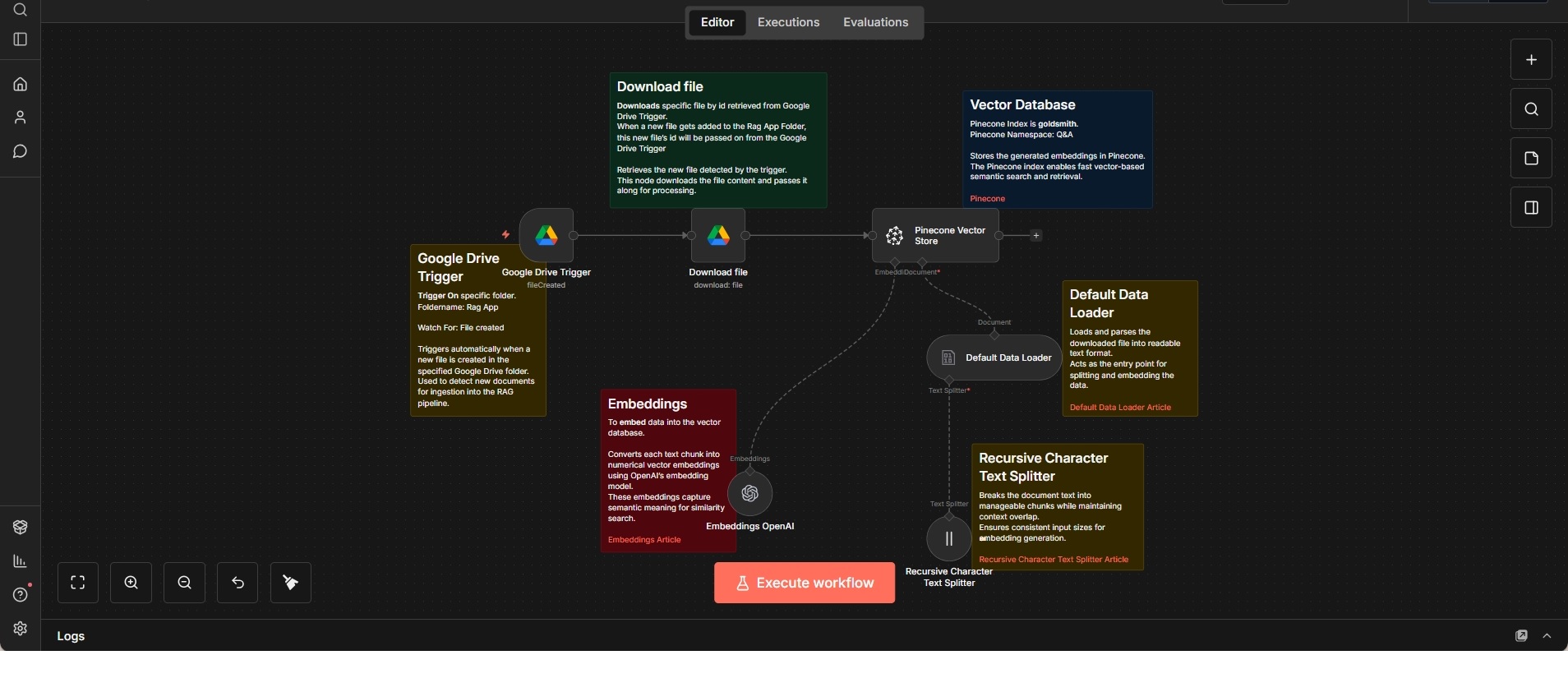
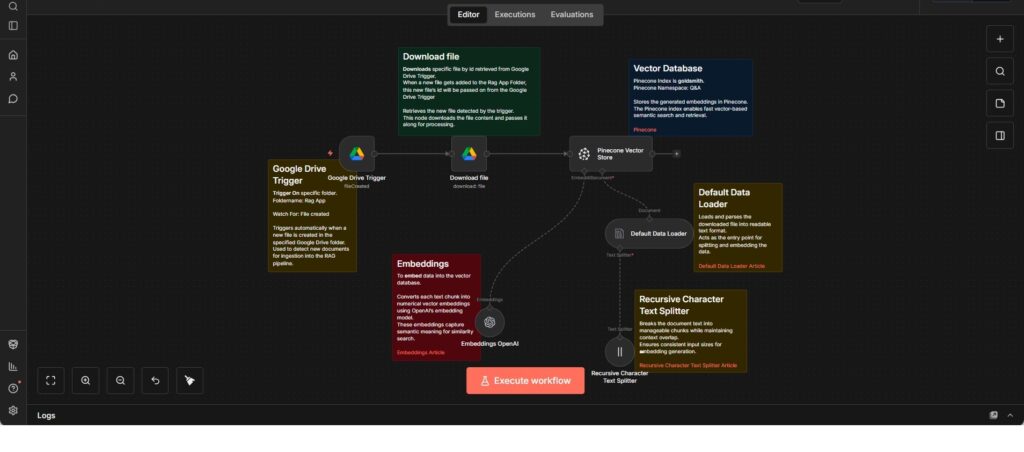
Dokumenten-Ingestion- und Embedding-Workflow
Ereignisgesteuerter Workflow, der neue Dokumente aus Google Drive verarbeitet und als Vektorembeddings in einer Datenbank speichert.
Dieser Workflow übernimmt die Ingestion neuer Dokumente in ein vektorbasiertes Retrieval-System. Er wird ausgelöst, sobald eine neue Datei in einem definierten Google-Drive-Ordner abgelegt wird, und lädt den Dateiinhalt zur Weiterverarbeitung herunter.
Nach dem Download wird der Dokumentinhalt in ein lesbares Textformat überführt und mithilfe eines rekursiven, zeichenbasierten Text-Splitters in handhabbare Abschnitte unterteilt. Dadurch bleiben Struktur und Kontext des Originaldokuments weitgehend erhalten, während konsistente Chunk-Größen sichergestellt werden.
Die einzelnen Textabschnitte werden anschließend mithilfe eines Embedding-Modells in Vektoren umgewandelt und in einer Pinecone-Vektordatenbank gespeichert. Die abgelegten Daten können später für semantische Suche oder RAG-basierte Anwendungen genutzt werden.
Der Datensatz mit dem Namen Goldsmith stellt ein fiktives Unternehmen dar und dient ausschließlich Test- und Entwicklungszwecken.
Der Workflow ist als klar nachvollziehbare Ingestion-Pipeline aufgebaut, bei der Dateierkennung, Inhaltsaufbereitung, Embedding-Erstellung und Speicherung sauber voneinander getrennt sind.
You must be logged in to post a comment.