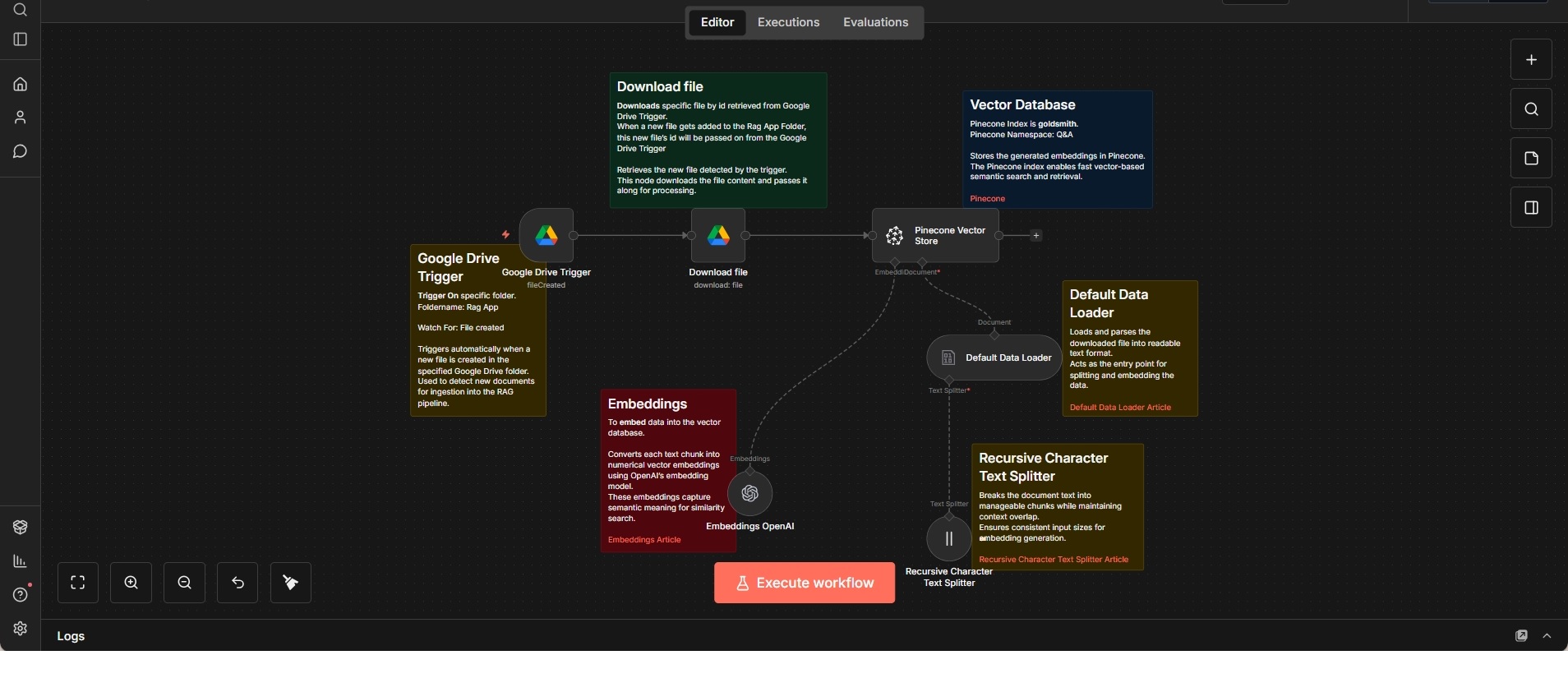
Document Ingestion and Embedding Pipeline
Event-driven workflow that ingests new documents from Google Drive, processes their content, and stores embeddings in a vector database.
This workflow handles the ingestion of new documents into a vector-based retrieval system. It is triggered whenever a new file is added to a designated Google Drive folder and retrieves the file contents for further processing.
After downloading the document, the content is parsed into a readable text format and split into manageable chunks using a recursive character-based text splitter. This ensures consistent chunk sizes while preserving the overall structure of the source document.
Each text chunk is then converted into vector embeddings using an embedding model and stored in a Pinecone vector database. The indexed data can later be queried for semantic search or retrieval-augmented generation workflows.
The dataset associated with Goldsmith represents a fictional company and is used purely for testing and development.
The workflow is structured as a clear ingestion pipeline, separating file detection, content preparation, embedding generation, and vector storage, making it easy to adapt or extend individual steps.
You must be logged in to post a comment.